ML Systems Architecture Design¶
👀 Overview¶
The creation and architecture of ML systems play a crucial role in the successful implementation of machine learning solutions. ML systems consist of various components, including data storage, preprocessing, model training, and prediction serving. Properly designing the architecture ensures that the system meets its intended objectives and functions effectively.
ML systems are subject to technical debt, which refers to accumulated problems in code and architecture caused by neglecting software quality during development. ML-specific technical debt includes issues like unstable data dependencies, feedback loops, pipeline complexities, and entanglement. Addressing these challenges is essential for maintaining the system's performance and facilitating future modifications.
Understanding ML system architecture is vital for several reasons. It provides a clear vision of the end product and guides decision-making throughout the development process. A well-designed architecture ensures system reliability, ease of maintenance, and scalability. Additionally, it promotes effective collaboration within the development team by establishing a shared understanding of the system's structure and functionality.
🎯 Goals¶
The primary goals of considering ML system architecture are:
- Define a clear and comprehensive architecture that aligns with the system's objectives and requirements.
- Identify and address potential technical debt specific to ML systems to ensure long-term maintainability.
- Balance development speed and reliability by making informed trade-offs during the architectural design phase.
- Enable seamless integration with existing infrastructure and tools, leveraging established practices and frameworks.
- Facilitate efficient data preprocessing, model training, and prediction serving processes within the system.
- Ensure scalability, allowing the system to handle increasing data volumes and user demands.
- Incorporate proper monitoring and error handling mechanisms to detect and resolve issues promptly.
- Promote collaboration and shared understanding among team members by documenting and communicating the system architecture effectively.
By achieving these goals, ML system architects can build robust and efficient systems that deliver reliable predictions and support continuous improvement and evolution of machine learning solutions.
🏗️ Creating and Architecture of ML Systems¶
ML Solution Architecture¶
ML Solution Architecture refers to the design and organization of components and processes within a machine learning system to create an effective and scalable solution. It involves determining the structure and interaction between various elements such as data ingestion, preprocessing, model training, evaluation, deployment, and prediction serving.
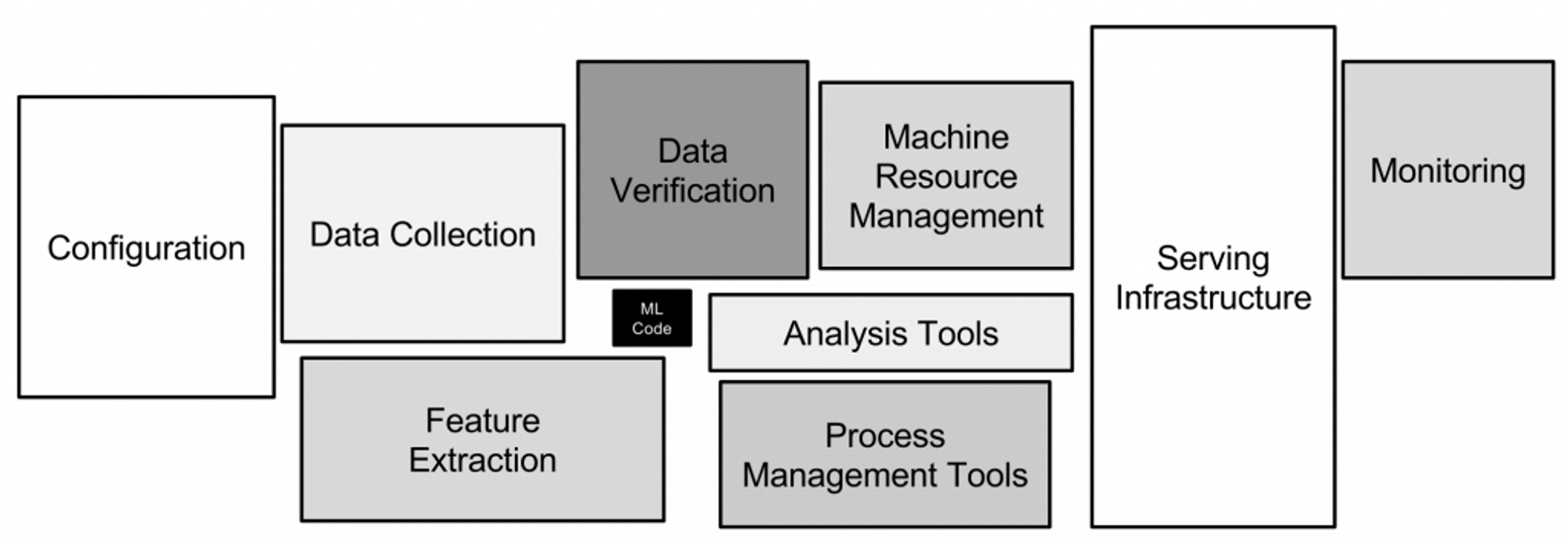
Key components and processes:
- Data ingestion: Collecting and acquiring relevant data for training and evaluation.
- Data preprocessing: Cleaning, transforming, and preparing data for modeling.
- Feature engineering: Extracting and selecting meaningful features from the data.
- Model training: Building and training machine learning models using the prepared data.
- Model evaluation: Assessing the performance and accuracy of trained models.
- Model deployment: Integrating the models into a production environment for real-time use.
- Prediction serving: Providing predictions or recommendations based on deployed models.
- Monitoring: Continuously monitoring the system's performance and data quality.
- Scalability and efficiency: Ensuring the system can handle large-scale data and user demand.
- Security and privacy: Implementing measures to protect sensitive data and ensure compliance.
A well-designed ML solution architecture enables the development of robust, scalable, and accurate machine learning systems. It ensures effective utilization of data, efficient model training and deployment, and reliable prediction serving.
Why should we care about this?
- Architecture describes the end product we need to build.
- Choosing an architecture dictates the strengths, weaknesses, and future modifications of the solution.
- Poor architecture leads to technical debt and problems in its operation, maintenance, and development.
- Effective teamwork requires a shared understanding of how your system is structured.
Technical Debt refers to the accumulated issues in software code or architecture that arise from neglecting software quality during development, resulting in additional future work and costs.
Note
ML Systems have additional "capabilities" for accumulating technical debt. ML Engineers encounter this first and foremost.
Examples include unstable data dependencies, feedback loops, glue code, pipeline jungles, dead experimental code paths, fixed thresholds in dynamic systems, entanglement (CACE principle), and more.
Initially, MLEs inherit all the problems and best practices from Software Engineering.
Creating ML Systems¶
Note
To make great products: do machine learning like the great engineer you are, not like the great machine learning expert you aren't. 😄
Source: Rules of Machine Learning
Best Practices for ML Engineering by Martin Zinkevich:
- Make sure your pipeline is solid end to end.
- Start with a reasonable objective.
- Add common-sense features in a simple way.
- Make sure that your pipeline stays solid.
Here are some rules for the ML system design development divided into the following phases:
- Before Machine Learning
- ML Phase I: Your First Pipeline
- ML Phase II: Feature Engineering
- ML Phase III: Slowed Growth, Optimization Refinement, and Complex Models
Requirements for Architecture¶
- Requirements for feature computation
- On-the-fly or precomputed?
- Which software tools will be used?
- Requirements for training
- How often?
- On which resources?
- Requirements for prediction serving
- How will predictions be served?
- How quickly?
- Minimum acceptable quality?
- Trade-off between development speed and reliability
Here's the information organized into a table format:
| Requirements | Important information |
|---|---|
| Requirements for feature computation | On-the-fly or precomputed features? Tools/frameworks for feature computation? Scalability/performance requirements? |
| Requirements for training | Frequency of training? Available training resources? Constraints/requirements for data handling? |
| Requirements for prediction serving | Method of serving predictions? Response time requirements Minimum acceptable prediction quality? |
| Trade-off between development speed and reliability | Development speed vs. reliability priorities Criticality of system reliability? |
| Requirements for autonomy | Autonomous operation or human intervention? Desired level of decision-making autonomy? Regulatory/compliance considerations? |
| Requirements for customizable processing | Need for data processing/model training customization Incorporating custom algorithms or pipelines? Modular and configurable components? |
| Requirements for handling private data | Privacy regulations/concerns? Security measures for private data? Data handling/encryption requirements? |
In this table, the requirements for architecture are listed in the left column, and specific details or questions related to each requirement are provided in the right column.
Feature Preprocessing¶
There are usually two approaches:
- Compute features in real-time
- Some features need to be precomputed
Using existing data sources introduces integration challenges and imposes constraints, such as response time.
A Feature Store is used to store features, which are utilized during both training and prediction serving.
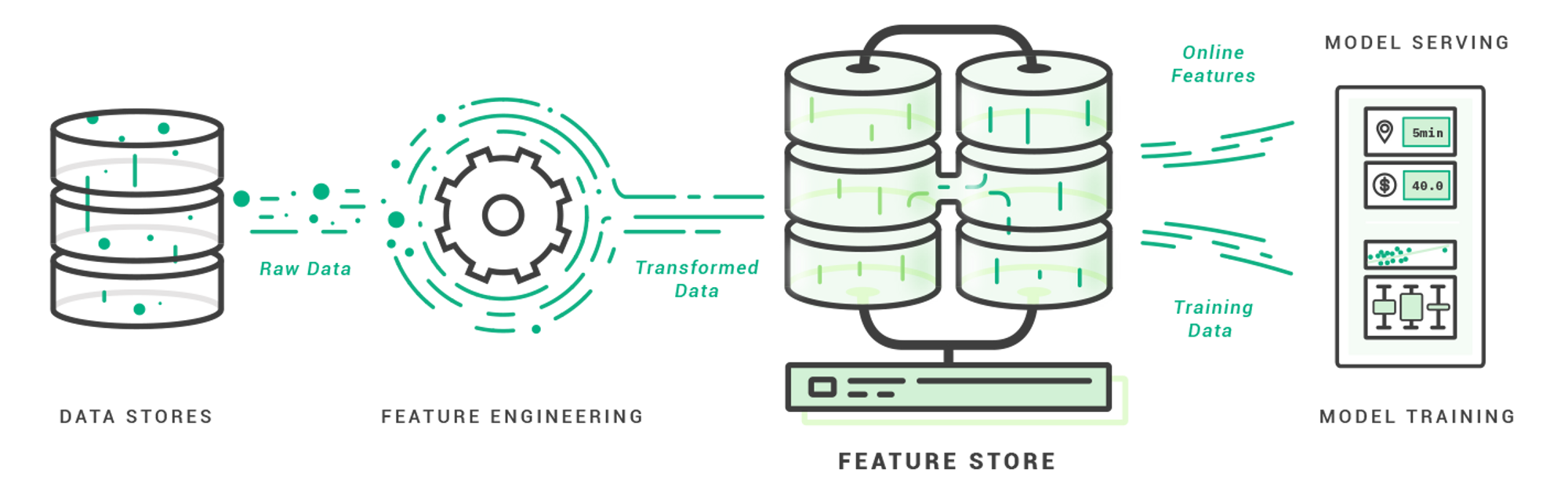
{kind=link}
For example, Hopsworks.
Training¶
- The most common approach is scheduled retraining - running code with cron jobs or task schedulers. (This is practiced in our course)
- Another approach is online learning (e.g., using Kafka and TensorFlow).
For example, Machine Learning in Production using Apache Airflow.
Prediction Serving¶

- Simple: Write a Python-based REST API wrapper (This is practiced in our course)
- Fast: Rewrite code in Go/C++ and use gRPC
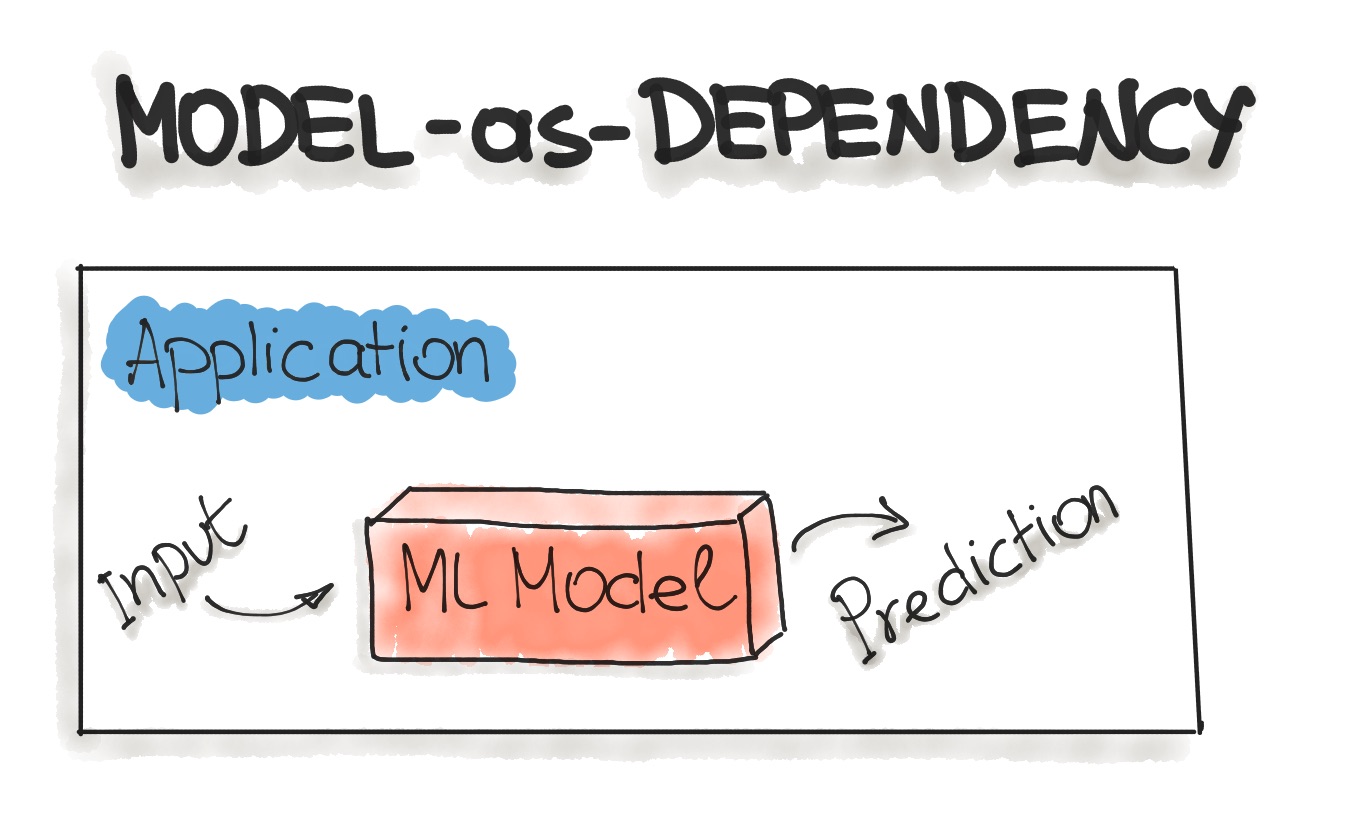
- In monolithic architecture applications
- In mobile applications

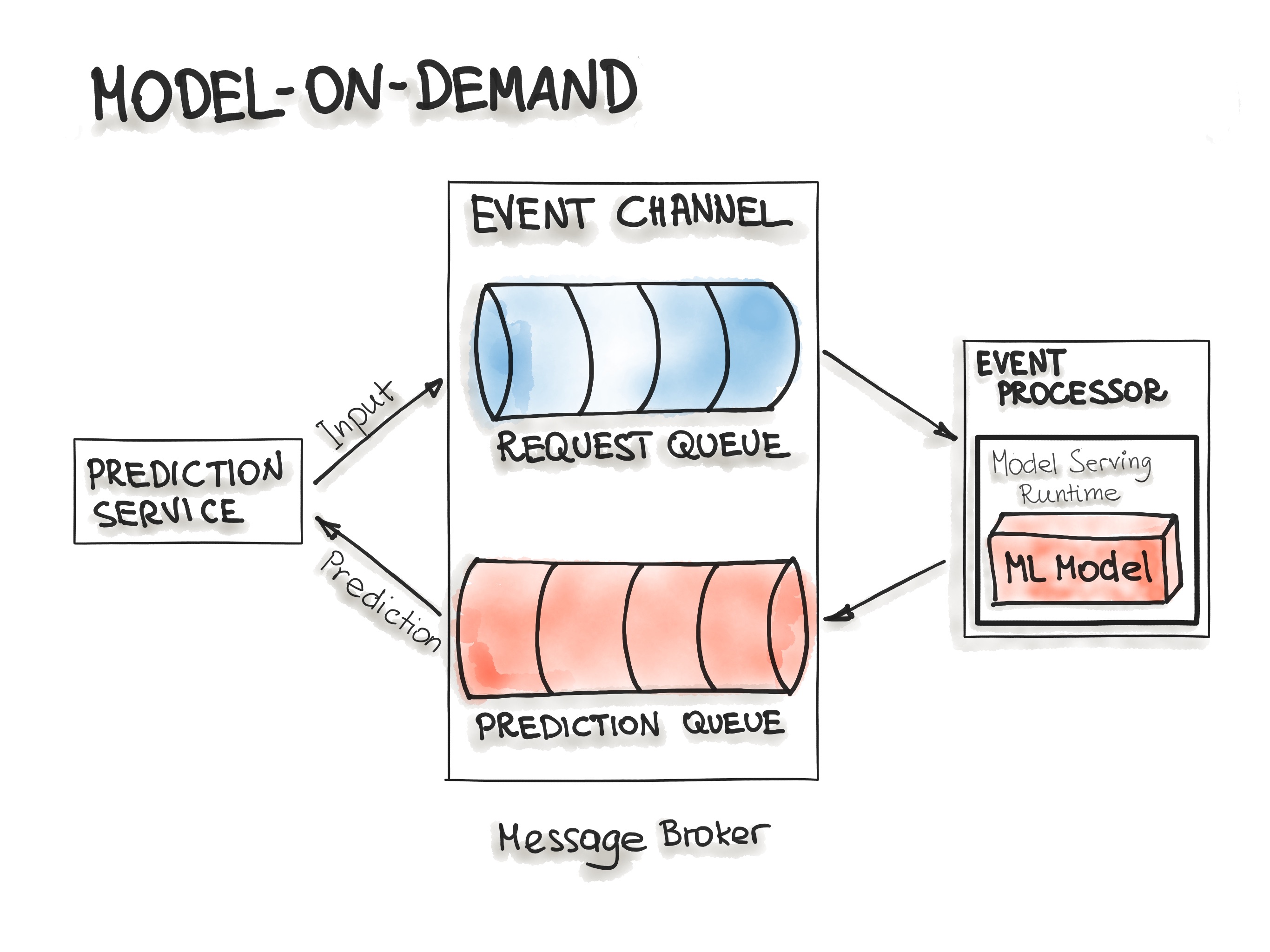
ML as a part of Existing Services¶
ML systems often arise on top of existing infrastructure:
- There is already a data warehouse.
- There is already a backend and established development approaches.
In such cases, it is typical to use existing tools and approaches. For example, using Airflow for running model training pipelines when it is already used in the company for ETL processes. Or deploying models on AWS SageMaker/OpenShift/Heroku when developers are already familiar with these platforms.
This can have both advantages (no need to build everything from scratch) and disadvantages (using inconvenient tools).
Examples¶
Example 1: Practice in our course¶
- Task: Daily user LTV forecast to prevent churn
- Architecture:
- Data is updated daily and available for download from Object Storage.
- Training occurs on a schedule.
- Real-time prediction using REST API queries.
Example 2¶
- Requirement: Fixed frequency of response to forecasts
- Example tasks:
- Daily user LTV forecast to prevent churn
- Hourly weather forecast
- Hourly energy consumption forecast
- Architecture:
- Data is collected from various sources and stored in a data warehouse (DWH), constantly updated.
- Scheduled training: Download fresh data (SQL), prepare the dataset, train the model.
- Scheduled prediction: Load the result into the database.
Example 3¶
- Requirements: Big data, high-load services requiring a high-speed response
- Example tasks:
- Maps: travel time from point A to point B
- Ad rotation
- Email spam classification
- Architecture:
- Data is collected from various sources (e.g., HDFS), features are computed (e.g., Spark), and stored in a Feature Store.
- Scheduled training: Download fresh data, prepare the dataset, train the model.
- Real-time prediction using gRPC queries, with code potentially rewritten in compiled languages.
🏁 Conclusion¶
- Architecture refers to the description and structure of software systems.
- Technical debt is the accumulated issues in software code or architecture that arise from neglecting software quality during development, resulting in additional future work and costs.
- ML systems have their own specific technical debt, which requires special attention and effort to address, in addition to regular development technical debt.
- Discussing architecture is best started by defining the system requirements. Key ML-specific requirements include feature computation, model training, and prediction serving.
ML systems encompass a wide range of components and considerations, from feature preprocessing to training and prediction serving. It's important to carefully design the architecture, taking into account the specific requirements of the system and considering the trade-offs between development speed, reliability, scalability, and other factors.
🎓 Additional Resources¶
- "Hidden Technical Debt in Machine Learning Systems" paper
- Rules of Machine Learning: Best Practices for ML Engineering by Martin Zinkevich
- Machine Learning Systems by Jeff Smith
- Three Levels of ML Software
- Clean Architecture: A Craftsman's Guide to Software Structure and Design, Robert C. Martin; Short video about it
- A Philosophy of Software Design (2018), John Ousterhout
- Machine Learning in Production using Apache Airflow
Contribute to the community! 🙏🏻
Hey! We hope you enjoyed the tutorial and learned a lot of useful techniques 🔥
Please 🙏🏻 take a moment to improve our tutorials and create better learning experiences for the whole community. You could
- ⭐ Put a star on our ML REPA library repository on GitHub
- 📣 Share our tutorials with others, and
- Fill out the Feedback Form We would appreciate any suggestions or comments you may have
Thank you for taking the time to help the community! 👍
